最短歧义串
问题描述
对于一个字符串,如果我们可以用两种不同的办法把它切分成单词的序列,那么我们说这个字符串是有歧义的.比如iskill,可以切分成is和kill,也可以切分成i和skill。
现在给你一个单词表,请你构造出在这个单词表上的最短歧义串,即这个串可以用两种方案切分成单词表中的单词,要求歧义串尽可能短。
输入
第一行是一个整数n (n<=100)表示词表的大小.
接下来n行,每行一个单词,只包含数字和小写字母,长度不超过20.
输出
输出最短歧义串,如果最短歧义串有多种可能,请输出字典序最小的那一个.
例子
4
i
is
kill
skill
skill
思路
看到题目,开始以为可以直接枚举,但其实是做不到的,因为歧义串不一定只由两个字串拼起来。必须要用其他的方法。
递归时,考虑如何处理子问题。其实,一个字符串有两种组成方法的话,它一定可以通过如下方法构建:
- 取一个串A做第一行的初始
- 取另外一个串B,使得B的前n位是A,或者A的前m位是B,作为第二行初始。

- A或B的未匹配部分(就是多出来的那块)作为新的A,

继续找对应的B,拼到短的那一行上,如此递归地寻找拼接上去的串。
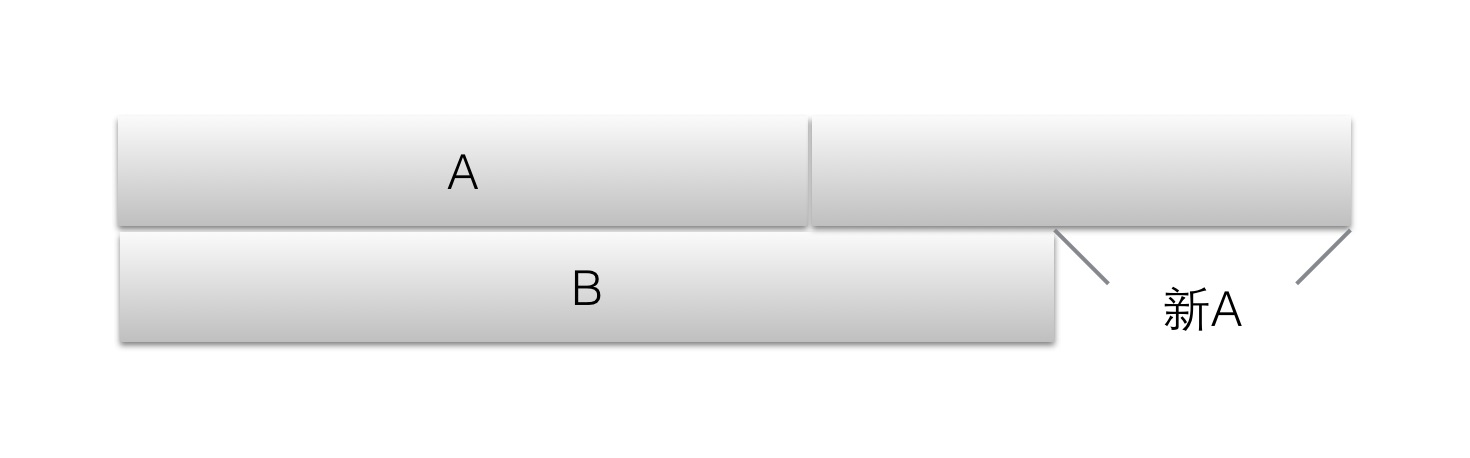
- 直到某次,字典中找到了一个串,可以完全填补未匹配部分,则匹配完成。

上面就是基本思路,类似砌墙,保证未匹配串是下一块“砖”的一部分,或下一块“砖”是未匹配串的一部分。
具体实现
上述的思路看上去比较清晰,但是有一些小细节需要处理。
第一次匹配
取定第一个串A之后,未匹配部分就是A本身。按照递归的思路,要尝试字典中的每一个串,看能否完成匹配。这时,如果再取A的话,势必能完成匹配,产生结果A。要处理这个问题。我的做法是:
if (strcmp(unmatched, temp) == 0)
{
continue;
}
unmatched是未匹配部分,temp是到目前为止的歧义串。如果temp与unmatched相同,说明这是第一次匹配。忽略第一次就匹配成功的情况。
往哪里加
这道题目其中一个麻烦之处在于,用两种方式生成了歧义串,但是难以记录,因为一会儿往第一行上加,一会儿往第二行上加。我的做法是,只记录第一行的结果temp,其中通过一个bool变量记录当前是在往第一行上添加还是第二行。也可以第一、第二行都记录,然后每次要拼接时,比较两行的长度,总是往短的那一行拼接。拼接完之后,新的unmatched就是两行的未匹配部分。
避免死循环
这个题目有产生死循环的可能。比如以下情况:
101101101101101101…
…101101101101101101
也就是同一个串交叉匹配,这样就停不下来了。我的解决办法是,同一个串在匹配时,最多连续用两次。这可以开一个数组记录连续匹配的次数。
处理完以上问题,本题基本上就可以顺利通过。这道题基本上是一个带回溯的搜索。
代码:gist.github.com/yangl1996/9f533d91804f1bae510b(打了一个又一个补丁,相当恶心的代码)